

案例背景及挑战:
某数字化金融科技公司通过自主研发的一站式数字化金融服务平台,为用户提供市场数据、财经资讯、投资社区、投资知识等服务;并通过集团旗下持牌券商,向客户提供港股、美股、A股通、新加坡股及澳股的股票交易和清算,融资融券,及财富管理等服务。该公司以用户为中心构建起连接用户、投资者、分析师、媒体、企业和机构的投资生态系统。通过旗下 品牌,集团为企业客户提供一站式ESOP解决方案、首次公开募股(IPO)分销、投资者关系和公共关系(IR&PR)等企业及机构服务,已成为多家知名企业信赖的合作伙伴;同时,富途信托为企业及高净值个人和家族提供一站式综合财富管理顶层架构设计,利用科技革新员工激励计划信托、家族信托、家族办公室等服务。
本次任务为通过从数据库作为源,经过Kafka以流的方式到GKE部署的Flink集群,数据通过集群的Flink服务进行计算处理后,数据存储在BigTable,BigTable在作为处理后的数据源流向BigQuery中进行数据的分析,最后使用Look Studio 作为一个数据可视化。为保证效率及数据的存储和可视化性,本过程中,数据可以使用BigTable来作为大规模计算后的数据存储,以达到存储的目的;使用BigTable 的数据来提供BigQuery的数据分析,最后使用Looker Studio 作为最终的一个数据分析的视图渲染,将数据以可视化的形式呈现,可以让数据变得更加直观和易于理解,提高生产效率。
架构如下图:
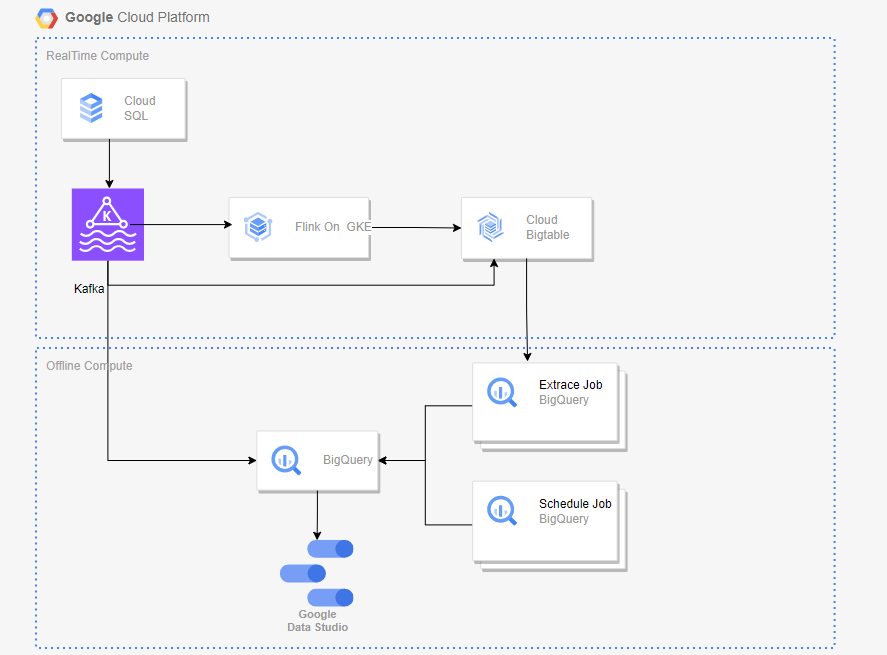
方案架构描述:
1.使用Bigtable替代Hbase,并在GKE上的flink会话集群中构建flink bigtable连接器
2.使用BigQuery替代Hive,将SQL DDL语句和作业从hive转换为bigquery
3.通过bigquery扩展表将bigtable中的数据提取到bigquery,达到百亿数据级别
4.在GKE上构建flink集群以进行自动缩放和资源管理,通过flink kafka连接器和flink bigtable连接器运行作业进行计算并将结果保存到bigtable
5.使用Bigquery Scheduler来调度由hive作业转换而来的bigquery作业
6.使用kafka连接器替换flink cdc作业将数据从kafka迁移到bigtable和bigquery
7.使用Looker Studio 作为数据的一个可视化,用来视图展示
使用产品:
Google Kubernetes Engine:作为业务部署的基础设施,提供业务自动扩缩,运行等。
Cloud SQL:代管式关系型数据库服务,存储数据的未经处理的初始数据。
BigTable:作为在GKE集群中处理过后的大规模数据存储。
BigQuery: 作为大规模的数据分析平台,并对数据进行评估。
Looker Studio: 具有极强灵活性的自助式商业智能平台,提供众多类型的吸引力的报告和数据可视化图表。
方案特点:
1.采用GKE部署Flink服务的集群,提供随时的自动扩缩和运行大量数据的计算,减少相应的维护和成本。
2.采用BigTable作为大量规模的数据存储,兼容 HBase 的企业级 NoSQL,低延迟,适用于大规模分析和运维工作。
3.采用BigQuery作为大规模数据的可视化分析,可根据您的数据量进行扩缩,提供实时分析,并对数据所在位置对其进行评估。
4.采用Looker Studio 作为最终的一个数据可视化分析平台,创建和分享极具吸引力的报告和数据可视化图表,具有更直观的智能化报告,将数据转换为有效的业务指标和维度。

